Getting started with Scrapy: A beginner's guide to web scraping in Python

I’d long been curious about web scraping and am pleased to have finally made a start in this direction. Previously, any scraping job I needed was carried out via import.io, but now I’ve branched out to Scrapy. I’d also wanted to practise my use of Python, so this was a great opportunity to kill two birds with one stone. Here I’ll share my first foray into this area - it may be useful for others who are also starting out (as well as for my future self, as a reminder).
I’m planning to do at least one more post on this same topic, but for now, we’ll start with a simple case where all the content we are interested in is on one single page - no need to cycle across multiple pages of results etc. A good candidate I’ve found is this page on LookFantastic, listing all their currently active discounts and vouchers. There are quite a few, but thankfully the page is fairly tidy, hence providing the perfect beginner case study. So here we go!
But wait, why should I bother?
Granted, this is just a toy example - but even here, there could be practical implications for scraping the offers. For instance, we might be interested in multiple e-shops selling a particular item, so it would be useful to know when an offer becomes active for that particular item. We could use scheduled tasks via cron and regularly scrape these sites, and then create an alert or email notification when a relevant offer appears. In fact, web scraping can be useful to design entire services of this nature (without knowing their infrastructure, Pouch or Honey may use some form of web scraping).
Libraries and tools
We’ll start by loading the necessary libraries. I should add that for the purposes of this post, I am using Anaconda v.2020.02, a Python 3.7 interpreter, and Scrapy v.1.6.0. Equally, a really handy sidekick is the Web Developer menu → Inspector tool within Firefox (there are equivalent tools in other browsers).
from scrapy import Selector
import requests
import html2text
import pandas as pdWith that taken care of, let’s get stuck in. At the time of writing, the code below works smoothly for the page I chose, but I cannot guarantee this will still be the case in the future (but you can see the current lay of the land via this offline copy of the page).
CSS and XPath Selectors in Scrapy
Based on the documentation,
Scrapy comes with its own mechanism for extracting data. They’re called selectors because they “select” certain parts of the HTML document specified either by XPath or CSS expressions.
So this is exactly what we are doing below: using a helping hand from requests which we loaded previously, we then extract the HTML content of this page:
url = "https://www.lookfantastic.com/voucher-codes.list"
html = requests.get(url).content
response = Selector(text=html)
# The start of the output from the get() method looks something like this:
response.get()
# '<html lang="en-gb" xml:lang="en-gb" dir="ltr" xmlns:og="http://opengraphprotocol.org...Now that we have extracted the HTML from the URL, we have to figure out how to access specific elements that are of interest to us. This is where Firefox’s Inspector comes in. When the Inspector is active and we hover over various elements on the page, this will highlight the relevant HTML code that governs them. For instance, we can quickly see that the class of each offer “chunk” is voucher-info-wrapper.
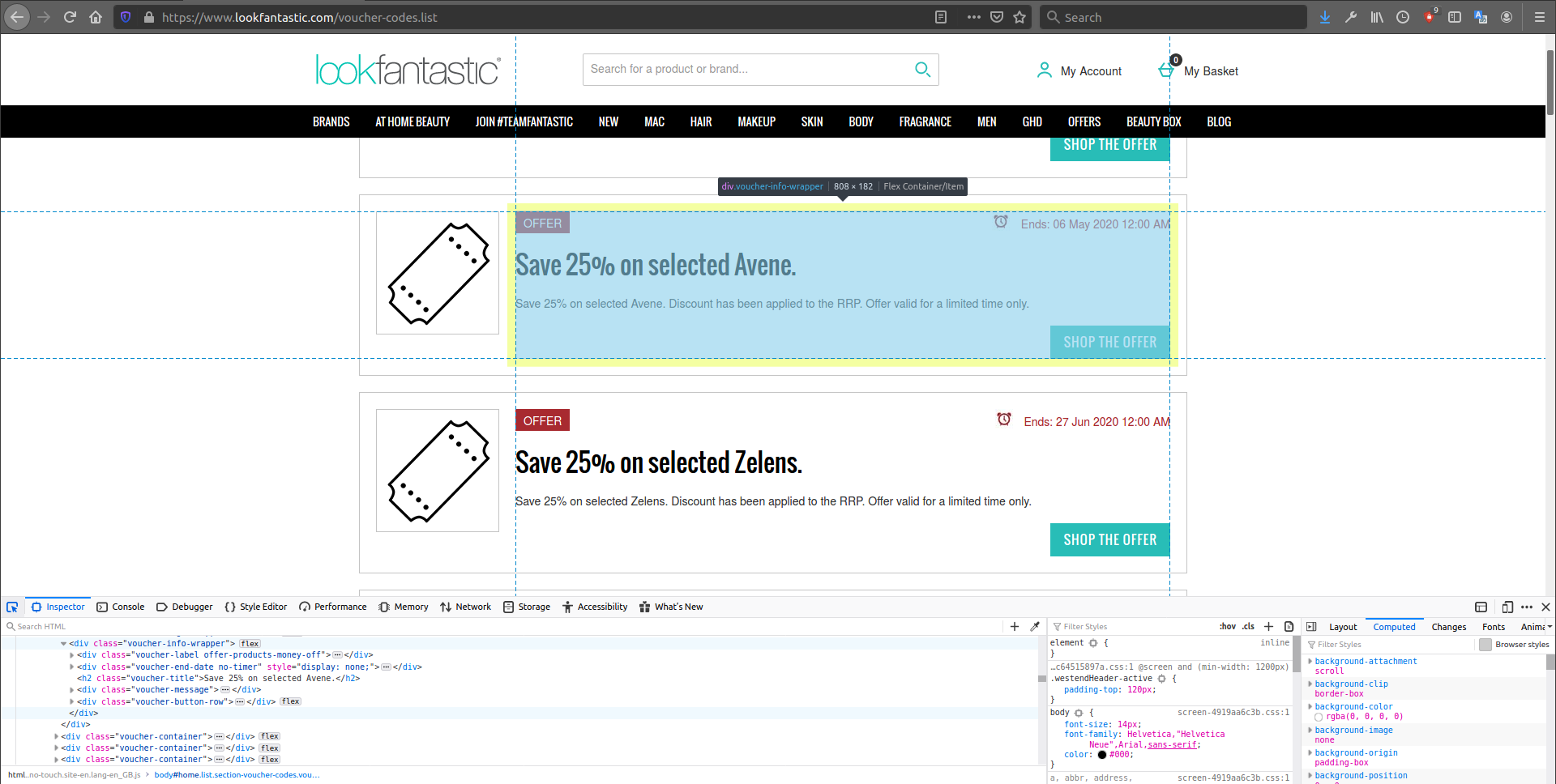
Bearing this in mind, we can use a selector in Scrapy to grab all the elements whose class is voucher-info-wrapper. The two methods below (CSS and XPath) lead to the same output: a SelectorList object. Depending on the task at hand, you’ll be able to use either CSS or XPath to extract the same information - the choice is up to you, although in some cases, it will be either the CSS or the XPath version which is more direct:
response.css(".voucher-info-wrapper")
# This is actually equivalent to:
response.xpath('//*/div[contains(@class, "voucher-info-wrapper")]')If you are wondering, the XPath notation //* here signifies that we are looking for our given class anywhere within the document. We can then explore the elements extracted using the get() or getall() methods:
response.css(".voucher-info-wrapper").getall()There are many ways to use selectors and have them take advantage of other element characteristics, not just class: for instance element id, or location relative to the rest of the HTML document. Here are some pairs of examples:
# 1) By location/structure:
# Let's grab the first div that's nested 6 'steps' deep within the Document Object
# Model (DOM, i.e., the hierarchy of elements on the page).
# Notice that we can also break up & chain selector commands:
halfway = response.css('html > body > div:nth-of-type(1) > div:nth-of-type(3)')
halfway.css( '.section > div:nth-of-type(2) > div:nth-of-type(1)').get()
# Or
response.xpath('/html/body/div[1]/div[3]/section/div[2]/div[1]').get()
# 2) By id (just an example, since our elements here don't actually have IDs):
response.css('div#SomeID').get()
response.xpath('//*/div[@id = "SomeID"]').get()Systematically extracting info to serve up as a pandas DataFrame
So now that we have a rough idea of how to use XPath and CSS selectors in Scrapy, we can target particular pieces of information from each offer. For (almost) any offer, we’ll observe:
- a title
- a main offer message/text
- a type of offer (discount, or nth product free etc)
- an end date
- a URL
So let’s start picking these off one by one:
# First, we grab all the offer elements via their class:
individual_offers = response.css('.voucher-info-wrapper')
# 1) Title
all_offer_titles = individual_offers.css(".voucher-title ::text").getall()
# The ' ::text' here extracts all the text associated with the elements of the
# 'voucher-title' class
# 2) Text
# We can attempt the same technique as above:
individual_offers.css(".voucher-message ::text").getall()
# However, by checking the length of the output with len(), we will notice that
# this is not consistent with the full number of offers that exist on the page (a
# simple check can be done via Ctrl+F for the 'Ends:' string directly via your browser).
# This is because some offers do not have any text at all within the 'voucher-message'
# elements. An alternative is to go over every offer, one at a time:
all_offer_messages = []
for offer_text in individual_offers:
current_offer_text = ''.join(offer_text.css(".voucher-message ::text").getall())
all_offer_messages.append(current_offer_text)
# An alternative to ' ::text' for extracting the text among html code:
strip_code = html2text.HTML2Text()
list_of_messages = individual_offers.css(".voucher-message").getall()
messages_stripped_of_html = [strip_code.handle(item) for item in list_of_messages]
# 3) Offer type
# The same element can have multiple classes simultaneously:
# A particular type of offer will have a specific class (e.g., money-off or cheapest-
# free), but there is also a general 'voucher-label' class that is applied across
# all offer types. We'll use this generic one first, and then use regex (and 're()')
# to find the other associated classes which code the *specific* type of offer:
offer_types = []
for offer in individual_offers:
current_offer_label = offer.css('.voucher-label').xpath("@class").re(r'offer-.*')
offer_types.append(current_offer_label)
# 4) End date
all_offers_end_date = response.css(".voucher-end-date::text").getall()
# And now for some minor cleaning:
all_offers_end_date = [deadline.replace("\t", "") for deadline in all_offers_end_date]
all_offers_end_date = [deadline.replace("\n", "") for deadline in all_offers_end_date]
all_offers_end_date = [deadline.replace("Ends:", "") for deadline in all_offers_end_date]
# 5) URL
# We start with a small DYI function that can handle empty inputs:
def xstr(s):
if s is None:
return ''
return str(s)
all_offers_URL = []
for link in individual_offers:
current_offer_label = "https://www.lookfantastic.com" +
xstr(link.css(".voucher-button::attr(href)").get())
all_offers_URL.append(current_offer_label)
# Now we will bring together all the info above as columns of a pandas DataFrame:
offer_df = pd.DataFrame({
'Title': all_offer_titles,
'Text': all_offer_messages,
# Flattening list of lists, also allowing for empty list elements:
'Type': pd.DataFrame(offer_types).fillna("").squeeze().tolist(),
'End': all_offers_end_date,
'URL': all_offers_URL
})
# And here is some final cleaning:
offer_df['Type'] = offer_df['Type'].str.replace('offer-products-', '')
offer_df['Type'] = offer_df['Type'].str.replace('-', ' ').str.capitalize()Final output
And voilà: we have scraped all the current offers on the LookFantastic site, and organised them into a tidy-looking DataFrame. The final output should look like this:
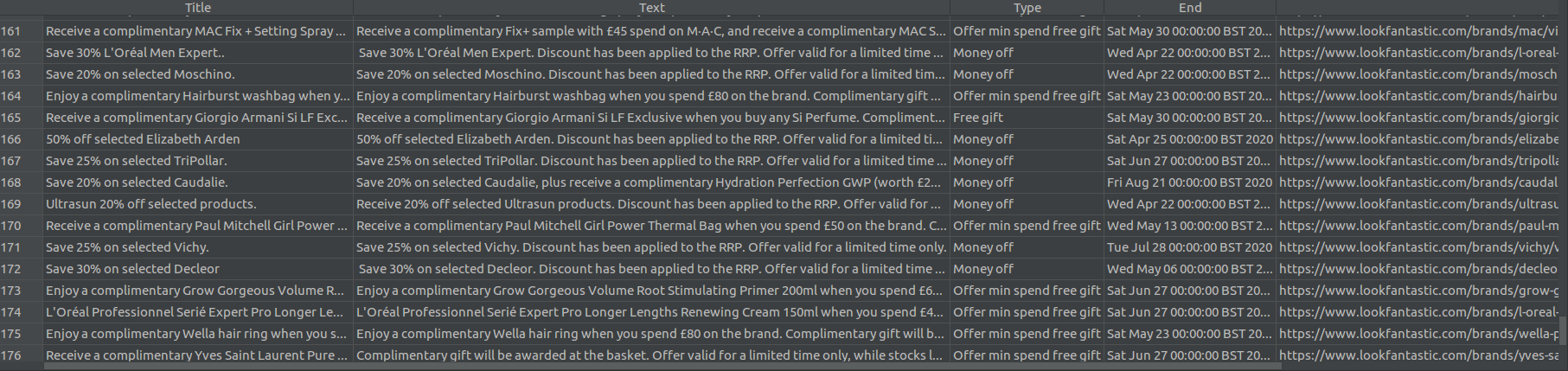
This is just a start, and I plan to add at least one more (complex) example. Until then, this should hopefully illustrate some of the basic things you can achieve with Scrapy.